

When you take nearly a decade to update your superbike (okay, eight years), you better do it with relish! That’s exactly what Suzuki has done. The new GSX-R1000 and limited edition GSX-R1000R promise all the goodies available in competitors’ machines and more.
Together with a three-axis IMU and advanced traction control and ABS, the electronic wizardry of the new machines meet a 199 horsepower all-new 1000 cc engine and a chassis with the latest suspension and brake components. The new superbikes are smaller and lighter, as well.
Here is information from Suzuki, together with photos and a nice video:
Suzuki has debuted two versions of its all-new GSX-R1000 at Intermot, with the GSX-R1000 and GSX-R1000R machines headlining the Cologne show.
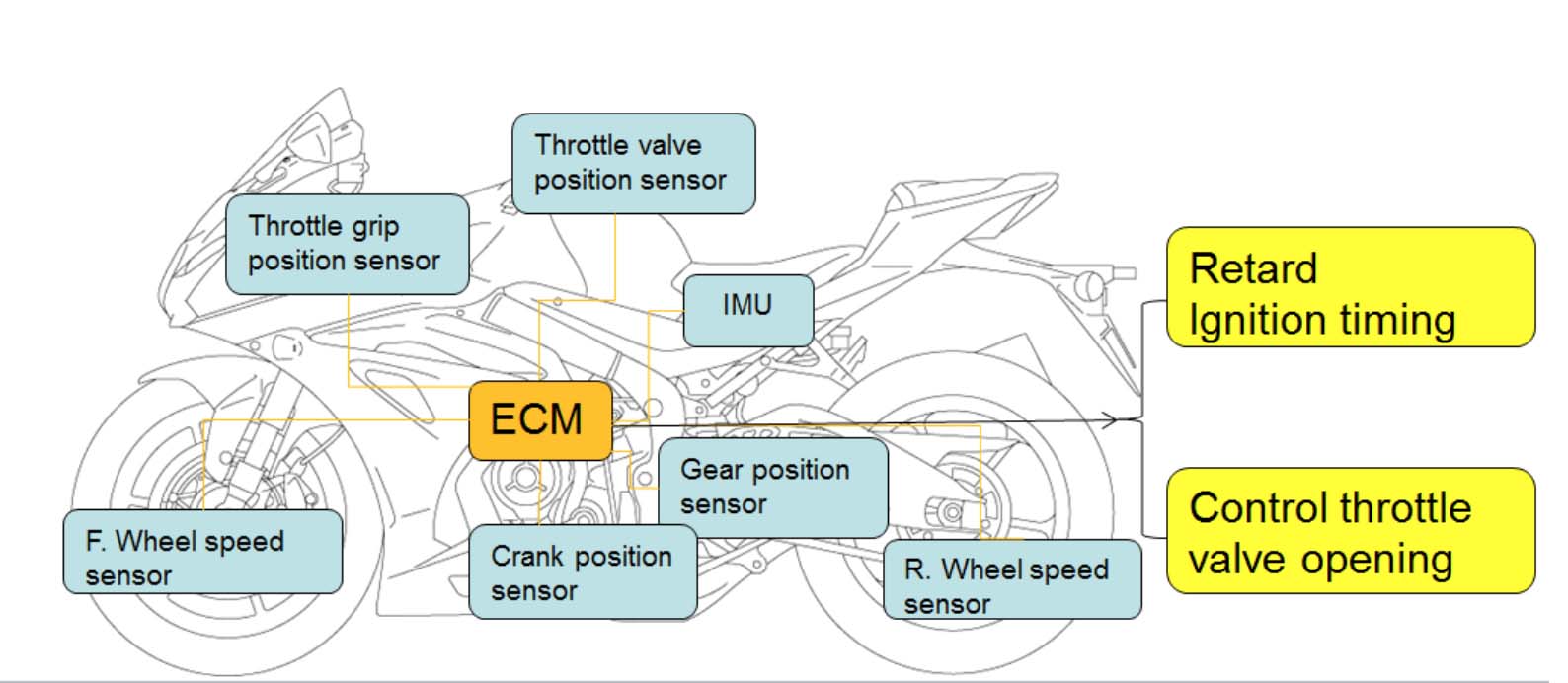
Designed and built from the ground up, both models feature a new frame and swingarm, wrapped around an engine that uses technology developed from the manufacturer’s race-winning GSX-RR MotoGP machine. That same MotoGP knowhow has also helped develop an extensive electronics package that features a three-axis inertial measurement unit (IMU) that works in tandem with a 10-mode traction control and sophisticated ABS systems.
GSX-R1000 & GSX-R1000R
Suzuki returned to the drawing board when it came to its flagship superbike, designing and building a brand new machine using technology developed from competition in MotoGP. The chief engineer on the project, Shinichi Sahara, used his experience as a former MotoGP technical manager and project manager to develop a new power-plant that produces 199.2bhp at 13,200rpm – Suzuki’s most powerful GSX-R engine, ever – to make sure the GSX-R1000 can reclaim its crown as the king of sportsbikes.
Both the GSX-R1000 and GSX-R1000R utilise an all-new, 999.8cc inline four-cylinder engine, which uses Suzuki Racing Variable Valve Timing (SR-VVT), and a new finger-follower valve train as part of Suzuki’s Broad Power System. Developed for use on the firm’s GSX-RR MotoGP racer, the system allows the new engine to produce strong low-midrange power, before the variable valve timing system boosts top-end output.


Suzuki’s SR-VVT is a compact and lightweight mechanical system, that is built into the intake sprocket and is activated by centrifugal force, while the new finger-follower valve train is 6g lighter than a conventional bucket/tappet system, and allows the engine to rev higher and increases top-end power, with reliability.
Careful thought and planning also went into the engine’s dimensions and layout, to enhance the bike’s cornering performance. The cylinder block incline angle is moved backwards by 6 degrees, reducing the engine length by 22.2mm, the benefits of which are increased front-end feel and increased stability.
Inside the engine there are new pistons, pins, and rings, as well as new camshafts and titanium valves for higher peak power.

Competition in MotoGP has also led to the development of Suzuki’s most comprehensive and sophisticated electronics package, which features a six-directional IMU, 10-mode traction control system, Suzuki’s Motion Track Brake System, and three-rider modes.
Setting the GSX-R1000R apart from the GSX-R1000 is the addition of a bi-directional quick-shifter and a launch control system that allows riders to make smoother, faster starts.
Both models utilise the ‘anti-stoppie’ function of Suzuki’s Motion Track Brake System, but only the GSX-R1000R benefits from its cornering ABS function.
Suspending the GSX-R1000R is the latest generation of Showa’s Balance Free front forks and rear shock, which give more controlled performance and improve front-end feel. The GSX-R1000 model utilises Showa’s Big Piston front forks and Showa shock.

See more of MD’s great photography:
![]()





re: “titanium valves”
Honda, are you seeing this…? talk to me goose.
I thought Suzuki would go The Honda way with its superbike…
Lean engine with a TON of reliability and excellent road manners yet still a bit of ‘poke’ for those who dare…
A real road superbike…
But then again, Suzuki has it covered with Gsx1000f…!
Anyhow, 200HP puts it right with The Panigale 1299, S1000RR, RSV4R and ZX10R…
Lets see…
But I’d take The GSX…! Never liked crotch rockets, probably never will…
I’m interested to see how the bike compares to its competition. Suzuki clearly put a lot into this one.
Bike overload! We live in the best of times. All these great new bikes and updated bikes are incredible. And a big thank you to motorcycledaily for keeping us up to date. It feels like Christmas in October:))
Indeed!
“finger follower” = desmo?
Not sure, but I think desmo has both down and up forced valve action (so it closes the combustion chamber faster(?) than a valve spring). As far as I (don’t) know finger followers are just a type of lever that connects the spinning camshaft to the actual valve, so just down (returns with springs). So, half desmo? 🙂
https://www.youtube.com/watch?v=fCB4-D9yITQ
Q: “finger follower” = desmo?
A: not so much. “finger follower” = Formula 1/BMW S1000RR. perhaps even half spherical shims. lose the buckets and you lose a gang of inertia.
After only the briefest perusal, this new SB looks very nice indeed. Very glad to see the styling finally grew up w/ the bike! (Hint: not many zit faced buyers of $20k SBs!)
I read just about everything Suzuki released on the 2017 GSX-R750 naked and 2017 V-Strom 650, both highly updated, the latter offering standard cast wheels or tubeless spoke rims (finally). Both bikes look like potential best in class models. Finally V-Strom styling appears to at least equal it’s considerable performance.
Take a look at both, plus other new models, GSX-R125 single, V-Strom 1k, etc.
Well, they certainly played it safe with the styling, if that’s what you mean. Aside from the muffler, I see nothing offensive here. Or inspiring. Or interesting.
Yes, I agree. At least this looks better than any prior GSX-R1000.
Among the 2017 SB designs, looks wise in descending order here’s my vote:
Yamaha
Close second Suzuki/Honda tie, maybe leaning toward the light blue GXS
Kawasaki still to “busy” and origami
re: “Well, they certainly played it safe with the styling, if that’s what you mean. Aside from the muffler, I see nothing offensive here. Or inspiring. Or interesting.”
yup kinda vague, amorphous. but i recognize they’re trying to channel the MotoGP racer so i’m going to wait till i see it in person before i dispense my own “private label” brand of justice.
Muffler getting bigger, bike getting smaller…
Emission regs.
All manufacturers have to deal with those same emissions regs, yet somehow the new Honda’s pipe is half the size of this one. There is no way this new Kawi’s pipe needs to be that ginormous.
Just look at the thing. I mean, my god….
Yeah, that pipe looks particularly large. 99% of the time thats the first thing a buyer replaces.
It looks an exhaust can going down the road with a small motorcycle attached to it.
+1!!
Is that a Suzuki exhaust in your pocket, or are you just happy to see me?
Thor’s hammer.
More than half the guys here don’t know who first said that (replace “exhaust” w/”gun.”) And she said it with style, baby!
a scrapper’s wet dream.
It needs a bigger exhaust 🙂
Yep apparently motorcycle exhaust is destroying the planet at such a voracious rate that we’ve come to this
That may just be the largest muffler ever fitted to a motorcycle. Sheesh.
I think it’s bigger than the one on my VW for Pete’s sake…
Look on the bright side. Replacing that giant garbage can will net you huge savings (if you don’t land in emissions jail).
That two minutes went FAST. Like the single headlight. Cool bike with lots of tech.
Nice, seems like a lot of new tech on the liter gixer, maybe this is the start of a new generation of bikes?
I will have to join now the “old CBR” complainers group :p
The reviews about the VVT are going to be interesting.